
Neuromorphic Computing {VC}
Solving the AI Hardware Problem


You’ve seen hundreds, if not thousands, of stories about GPT and AI this year.
In fact, you’re probably experiencing some form of GPT Fatigue and are tired of hearing about it.
And you’re not alone—just look at the Google Trends:

Aside from the basic “enough already!” impulse that comes from hearing the same thing for the nth time, I also think we’re seeing the pushback of psychological self-preservation that I outlined in the Dark Side of Democratization.
Well, consider this intro a TRIGGER WARNING because this post will be about AI. . . albeit not in the way you think it might be.
I’ve been wanting to share a theme with you that I recently uncovered in my venture capital work, and with OpenAI filing their trademark application for GPT-5 (which will allegedly bring us to Artificial Generalized Intelligence), why not share it with you now.

GPT is shattering nearly every technology adoption record out there.
It hit 100 million users in just two months, and the amount of money people are spending on AI-powered apps is up 4000% YoY.
We all understand that the demand for AI is hitting a wave of exponential growth, but there is a critical bottleneck in supply that will slow down our ability to get to GPT-6, GPT-7… GPT -X, etc.
Language learning models (software) depend on powerful hardware, both when they are trained and when they are used.
Thus far NVIDIA GPUs have been powering most, if not all of this activity. Companies like NVIDIA make great GPUs, but these were initially optimized for rendering video games, not AI algorithms.
To use these GPUs requires high cost infrastructure and data centers (for example, it took $100M in compute to train GPT-4).
This may be ok for when you’re using a centralized AI service, but what if you want your car to have a localized AI? Or a private AI that’s not connected to the internet?
It’s simply unfeasible to attach a giant server rack to edge computing and “Internet of Things” use cases.
There’s a need for a complete ground-up redesign of this hardware, and that’s where neuromorphic chips come in.
Neuromorphic chips are semiconductors designed to mimic the human brain. Their radically different architecture allows for a much higher efficiency on AI-related tasks than what traditional setups can provide.
Let’s look at a breakdown of the differences.
Traditional Chips:
Have a basic structure of transistors, which operate like on and off switches for electrical impulses.
Operate using digital processing, which means every signal is encoded into either a 0 or 1.
Separate memory (RAM) and processing (CPU), which means data must be moved between these areas, thus creating potential for bottlenecks.
Neuromorphic Chips:
Utilize a brain-inspired structure that includes artificial neurons and synapses.
Among other aspects, this allows for a 3D configuration that connects transistors in multiple directions, as opposed to just on a flat surface. These connections lead to a higher density that enables less use of space while lowering power consumption (shorter distance for signals to travel).
Consider the analogy of moving from a single lane road to a multi-lane highway. In the former case, cars (data) can only go one way or the other, and if there's a lot of traffic, things can get slow and backed up.
In the latter case, cars (data) can move freely and quickly, without getting stuck in traffic. They can even take shortcuts, like a carpool lane, to get where they're going even faster.
Operate using analog processing. This means they can handle a continuous range of values, not just 0s and 1s, and it allows them to more closely mimic the way biological neurons work.
Integrate memory (RAM) and processing (CPU). In Neuromorphic computing, memory and processing are co-located, similar to how neurons and synapses are integrated in the brain. This eliminates the need to move data back and forth, improving efficiency.
By analogy, imagine having a kitchen (processing unit) and a pantry (memory unit) that’s located across the hall. Every time you need an ingredient (data), you have to walk across the hall to the pantry (memory). Once you've used the ingredient in your meal (processed the data), you have to walk it back to the pantry to store it again. This back-and-forth is time-consuming and tiring.
With Neuromorphic computing, it’s like having a built-in pantry in the kitchen that you can quickly reach into for ingredients. Everything is close at hand, so there's no need to walk back and forth across the hall.
This close integration of the kitchen and pantry (processing and memory) makes cooking (computing) faster and more efficient. You can prepare meals (process data) without the time and energy of walking back and forth to a separate pantry (moving data between separate processing and memory units).
The points above highlight the differences between traditional computing and neuromorphic computing.
Not to overcomplicated things, but if we do a direct comparison between GPUs and Neuromorphic chips we could consider a few additional analogies:
Orchestra vs. Jazz Band:
GPU (Orchestra): A GPU is like an orchestra where each musician (core) plays a specific part in unison with others, following a precise score (program). It's highly coordinated and can create beautiful, complex music (process large datasets) but requires strict adherence to the written notes (instructions).
Neuromorphic Chip (Jazz Band): A neuromorphic chip is like a jazz band where musicians (artificial neurons) improvise and play off one another, adapting to the mood and the audience (inputs). It's more flexible and can create unique, evolving music (learn and adapt) but doesn't follow a strict score (program).
Highway vs. Network of Paths:
GPU (Highway): A GPU is like a multi-lane highway where many cars (data) travel in the same direction at the same time. It's efficient for getting a large number of cars from point A to point B quickly (parallel processing) but doesn't allow for much deviation from the main route (fixed instructions).
Neuromorphic Chip (Network of Paths): A neuromorphic chip is like a network of interconnected paths where walkers (data) can take various routes, explore, and even create new paths (connections between neurons). It's more flexible and allows for exploration and learning but isn't designed for mass, uniform movement.

With this understanding in place, let’s consider again a real-world application, such as a self-driving car, which is a common use case for edge computing.
The car's sensors generate an immense amount of data that must be analyzed instantly to make safe driving decisions. Sending this information to a remote data center for processing would create delays that could introduce unacceptable latency 💥.
With a neuromorphic processor, however, the car can handle this data analysis on-board. Since the memory and processing are co-located, the system can operate more efficiently, minimizing both energy consumption and the lag in data handling. This integration enables the car to make quick, real-time decisions, which is a critical factor in ensuring both safety and smooth operation.
Other use cases that will soon be enabled by these chips include “self-driving” microscopes and automated inspection in manufacturing.
With concepts like “neural networks” in machine learning already having existed for some time now, you might be thinking: “Is this concept of mimicking the human brain really all that new?”
Yes, it’s true that this design inspiration has already been implemented at massive scale, but up until now it has only impacted the software layer.
What’s happening now is a radical hardware-software-codesign, where the chips (hardware) themselves are also being designed like the human brain, such that there is a much cleaner synergy between the software and hardware layers, since BOTH will now utilize the concept of neurons and synapses.
Sam Altman, founder of OpenAI, was an early investor in the neuromorphic company I recently analyzed and invested in myself. The company is already worth $250M at the current Series A round, and they don’t even have their first product ready yet (which goes to show you how serious this new technology is expected to be).
The long and short of it is that if you combine this upcoming hardware innovation, along with the next generation of LLMs, 2024 is going to be INSANE.
Let’s keep at it and stay ahead of the wave. And as always with these VC posts, if interested in learning more or investing yourself, reach out to me.
—Drago
P.S.
Out of curiosity after writing this, I did a Google Trends search for “LLM”, and it remains strong.
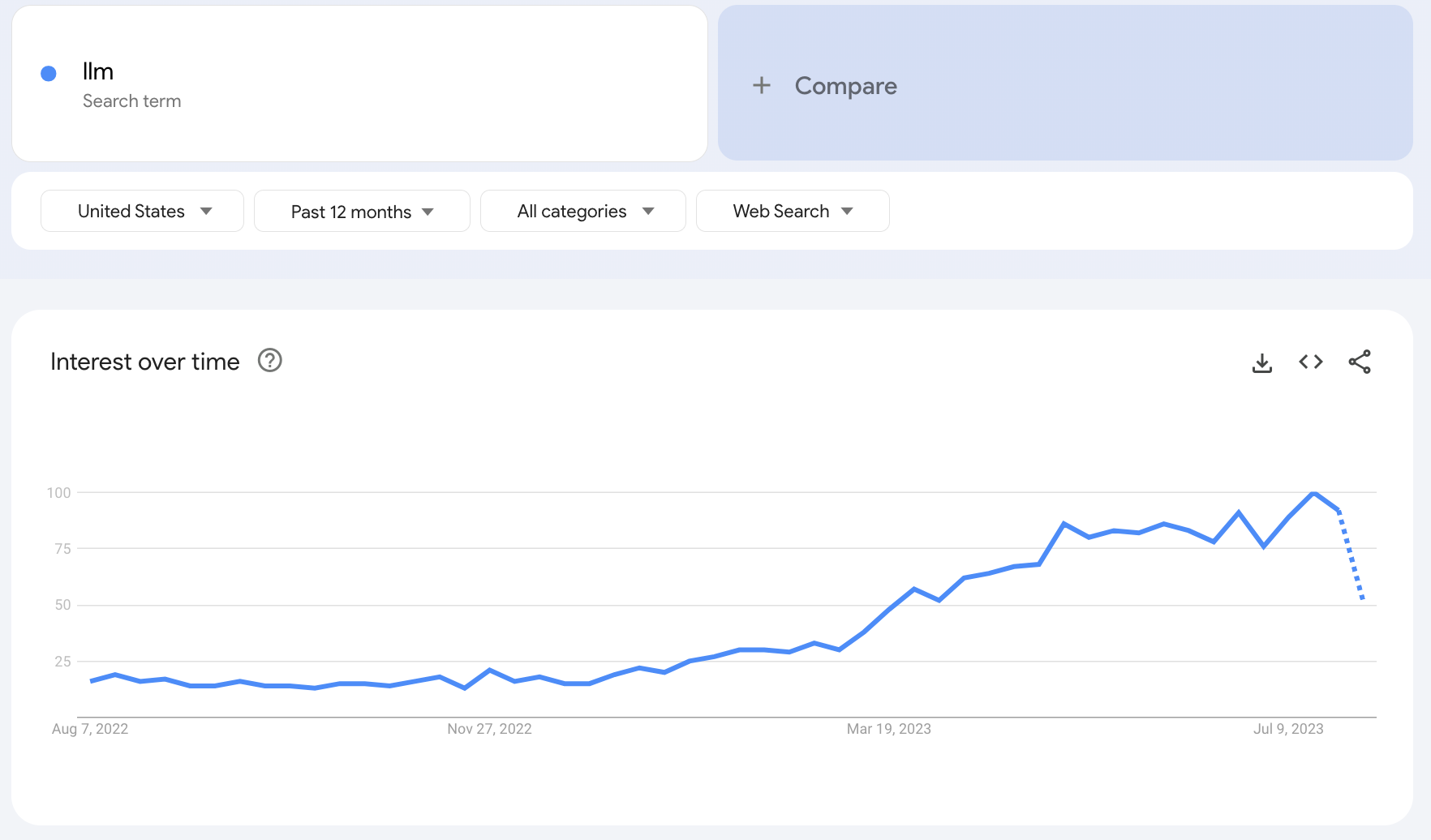
Do you think the combination of this trend + the declining trend of “GPT” reflects:
A) The gaining share of other LLMs like Bard and Claude.
B) The difference in the type of person who says “GPT” vs “LLM” (where “GPT” might be the more common term that a layperson searches and “LLM” is what an enthusiast would search for).
C) Something else ?